Introduction
A natural progression in the field of computer vision following unprecedented progress in image classification tasks is towards video and video understanding, especially how it relates to identifying human subjects and activities. A number of datasets and benchmarks are being established in this area1.
In parallel, further progress is being made in 2D image related computer vision tasks such as fine-grained classification, image segmentation, 3D image construction, robot vision, scene flow estimation and human pose estimation.
As part of my final Data Science project at Metis bootcamp, I’ve decided to marry these two parallel tracks - video and human pose estimation in specific - to create a content-based video search engine. Since applying 2D human pose estimation for video search is a novel idea with “no proof of concept”, I have simplified my approach by selecting single performer, fixed location single camera video footage of Salsa dance videos.
Video
Users on YouTube, the second largest search engine after Google, watch over 1 billion hours of video every single day. Users on Facebook, the most popular social networking site in the world, watch about 100 million hours of video every single day!! These platforms are interested in providing tools to their users in searching and discovering interesting and relevant content.
The tools these platforms provide for searching primarily use a video’s metadata (location, time, content creator etc.), titles, descriptions, transcripts (either user created or machine generated from audio), user ratings, user comments etc. in retrieving ‘similar’ results. These search tools do not skim the actual content of the video itself. Video is not skimmable or indexable for searches.
The visual features in the videos are too many and they are computationally expensive to index and too slow to retrieve. As a example, if one were to search for the steps of the Salsa dancer in exhibit 1, currently there are no tools available for the user on platforms like YoutTube. The salsa steps do not have textual context to perform a search.

Exhibit 1: Salsa Dance Video (Credit: World Salsa Summit 2016. Dancer: Valentino Sinatra, Italy)
The video search engine I built as part of my Metis Project 5, has indexed about 70 minutes of Salsa dance videos from YouTube and will return a match as shown in the exhibit below. The Salsa steps performed by Yeifren (in the middle) and Adriano (on the right) are similar to Valentino’s (on the left). In these clips, the performers walk back to the center of the stage and perform a number of turns as they face towards left of the stage.

Exhibit 2: A search results from the Video Search Engine (Credit: World Salsa Summit 2016. Dancers: Valentino Sinatra, Italy; Yeifren Mata, Venezuela; Adriano Leropoli, Montreal)
Upate One very subtle movement between Valentino (left) and the retrieved clip of Yiefren (center), is they both touch/hit their knees/legs!! The timing of it in the clips is off, but the model picks up on this!! I’ve watched these clips for many days before I even noticed it! I think its a fascinating result.
Methodology
There are two primarily steps in building the video search engine. First step is to download & process the video footage and run it through OpenPose for feature extraction. OpenPose is a human pose estimation algorithm developed by Carnegie Mellon University researchers (Zhe Cao et al). More on OpenPose is presented in the later sections. Second step is model building and testing query metrics. Models were built using matrix decomposition methods (PCA, LSA, NMF). Euclidean distance and cosine similarity were tested as query metrics. A feature engineering/feature representation exercise was also performed as part of this second step - flattened features and Hu moments of the features for each frame were tested.
The best combination of “feature representation/dimensionality reduction/query metric” obtained was by using plain flattened pose estimates with LSA and cosine similarity.
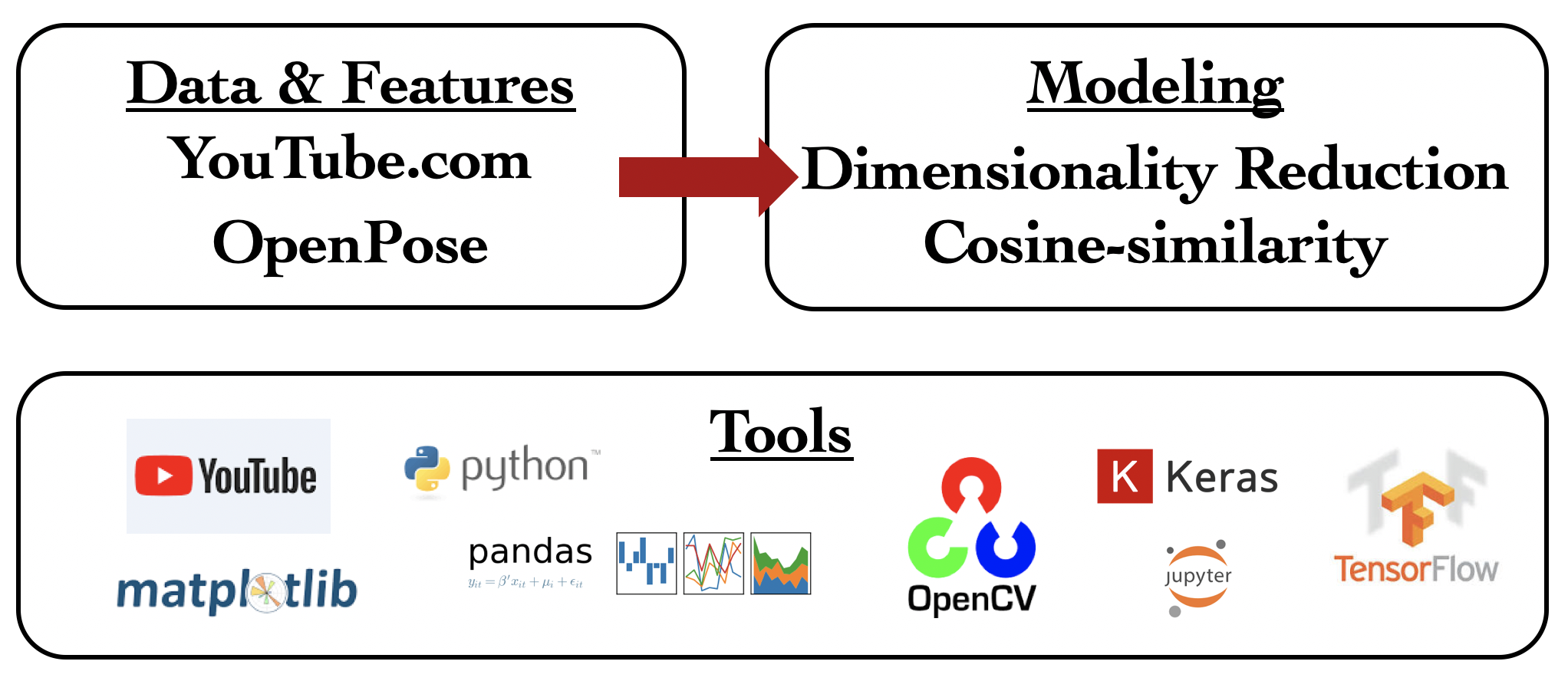 Exhibit 3: Methodology for building a video search engine
Exhibit 3: Methodology for building a video search engine
Data
The data for this project come from processing YouTube salsa videos (links below).
Why Salsa?
Besides being a challenging dance form that involves subtle and quick movements, a number of channels on YouTube provides easy access to videos with solo dancers. The Zhe Cao et al’s pose estimation user for feature extraction for my project is fast and accurate with multi-person video frames, but those algorithms do not track a person from frame to frame. This poses a problem when persons in a video switch places - read couples performing turns/lifts etc. To avoid this and simplify my problem, I’ve selected solo dance videos.
The other dance form that I have considered is ballet. However, the female dancers clothing (read tutus!) in ballet results in false positives as knees for certain dance poses that are common in ballet.
Salsa dance footage I have collected is from the following four videos with total run time of 160 minutes. This footage is processed down to 70 minutes and formatted into 3 second clips. The processed video consists of about 58 performances by about 30 artists. The videos are:
- https://www.youtube.com/watch?v=4nHElVbT3HY
- https://www.youtube.com/watch?v=ITNiqNcl6Mw
- https://www.youtube.com/watch?v=L5mqL7ADEsY
- https://www.youtube.com/watch?v=M_rPhEjym1o
To summarize, the videos used consists of:
- Single dancers
- Footage of single camera with fixed location (no moving cameras!). Only camera angle and zoom level are reflected in the footage.
- Reduced video frame rate of 8 frames per second (fps), down from the original rate of 24 fps.
- Fixed screen resolution at 640 (width) X 360 (height) pixels.
- About 70 minutes of processed footage and formatted into 3 second clips (over 1,400 observations).
OpenPose: Realtime 2D Multi-person Pose Estimation Algorithm
Human pose estimation is a computer vision problem of identifying anatomical “key points” of people in images or videos. In the last few years, a number of researchers have made incredible progress and demonstrated real-time performance2,4. Zhe Cao et al, from The Robotics Institute of Carnegie Mellon University have won inaugural COCO 2016 keypoint challenge using a “bottom-up” approach. They have achieved real-time speeds using GPU installed laptops.
Pose estimates are used in classifying human activity in images/video clips. They are primarily applied to 2D images, but never been used for video search objective. Below is an example of how OpenPose identifies 18 keypoints on a person in 2D images (for simplicity only 14 keypoints are shown).

Exhibit 4: OpenPose on a 2D Image Identifying Keypoints
When keypoints are identified for each frame in a video, the result will look as shown in Exhibit 5 &6 below.

Exhibit 5: OpenPose on a Salsa Dance Video Identifying Keypoints

Exhibit 6: Spatio-temporal features extracted from OpenPose
Results
A few results from indexing the salsa videos and performing a search using cosine-similarity are shown below. The top right video is the search clip, and the search results should be read from left to right, and then top to bottom.
Note that the search engine indexing is sufficient and effective in retrieving video clips where the dancers are just walking to their spots (Exhibit 7). This is an interesting result in itself, and demonstrates how this indexing method can be used for video editing. Manual editing of these clips will take hours even for “small” unprocessed footage of 2.5 hours, while the search engine takes less than a second to run and is capable of finding all such clips in the footage.

Exhibit 7: Search using a Clip of Dancers Making an Entry
A few more results



Other Applications
A video search engine like this has a number of applications. A few are listed below:
Exhibit 8: Other Applications for Video Search Engine
I have a few more ideas on how platforms like YouTube and Facebook can use video search on their current websites. A few conceptual ideas are shown below:
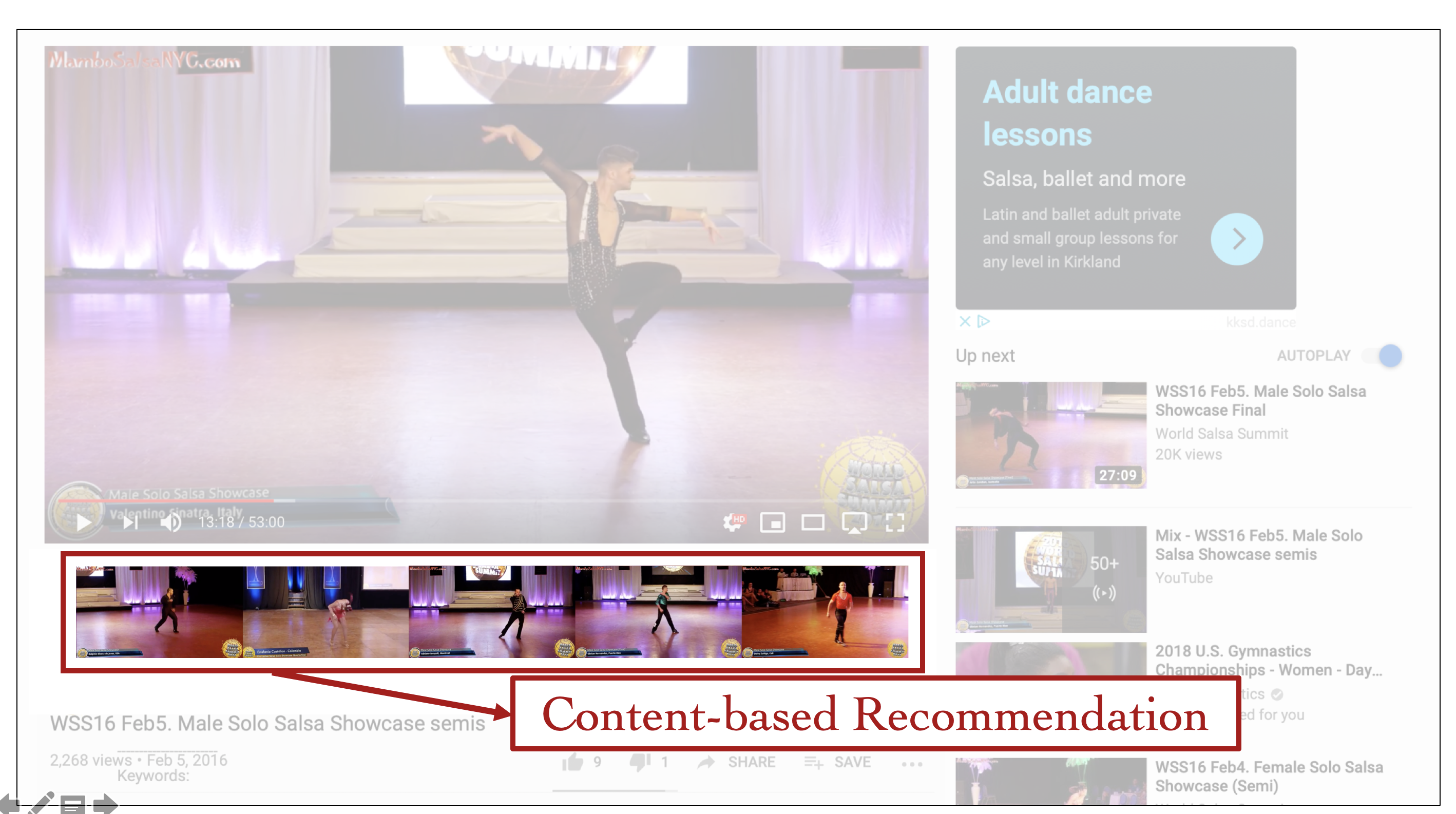
Exhibit 9: A Conceptual Layout of Video Search on YouTube Salsa Videos

Exhibit 10: A Conceptual Layout of Video Search on YouTube Football Game Videos